What is a task?
Tasks are defined as decorated Python functions. Above,explain_tasks is an instance of a task.
Tasks are cache-able and retryable units of work that are easy to execute concurrently, in parallel, and/or with transactional semantics.
Like flows, tasks are free to call other tasks or flows, there is no required nesting pattern.
Generally, tasks behave like normal Python functions, but they have some additional capabilities:
- Metadata about task runs, such as run time and final state, is automatically tracked
- Each state the task enters is recorded, enabling observability and state-based logic
- Futures from upstream tasks are automatically resolved by downstream tasks
- Retries can be performed on failure, with configurable delay and retry limits
- Caching enables result reuse across workflow executions
- Concurrency via
.submit()and.map()allow concurrent execution within and across workflows - Timeouts can be enforced to prevent unintentional, long-running operations
Running a task
A task run is a representation of a single invocation of a task.The life of a task run
Like flow runs, each task run has its own state lifecycle. Task states provide observability into execution progress and enable sophisticated runtime logic based on upstream outcomes. Like flow runs, each task run can be observed in the Prefect UI or CLI. A normal task run lifecycle looks like this:Background tasks have an additional stateWhen using
.delay(), background tasks start in a Scheduled state before transitioning to Pending. This allows them to be queued and distributed to available workers.Different ways to create a task run
The simplest way to create a task run is to call a@task decorated function (i.e. __call__), just like a normal Python function.
Task orchestration model
Client-side orchestration
Prefect tasks are orchestrated client-side, which means that task runs are created and updated locally. This allows for efficient handling of large-scale workflows with many tasks and improves reliability when connectivity fails intermittently. Task updates are logged in batch, leading to eventual consistency for task states in the UI and API queries.State dependencies
Tasks automatically resolve dependencies based on data flow between them. When a task receives the result or future of an upstream task as input, Prefect establishes an implicit state dependency such that a downstream task cannot begin until the upstream task hasCompleted.
Explicit state dependencies can be introduced with the wait_for parameter.
Task composition within flows
Tasks are typically organized into flows to create comprehensive workflows. Each task offers isolated observability within the Prefect UI. Task-level metrics, logs, and state information help identify bottlenecks and troubleshoot issues at a granular level. Tasks can also be reused across multiple flows, promoting consistency and modularity across an organization’s data ecosystem.How big should a task be?Prefect encourages “small tasks.” As a rule of thumb, each task should represent a logical step or significant “side effect” in your workflow.
This allows task-level observability and orchestration to narrate your workflow out-of-the-box.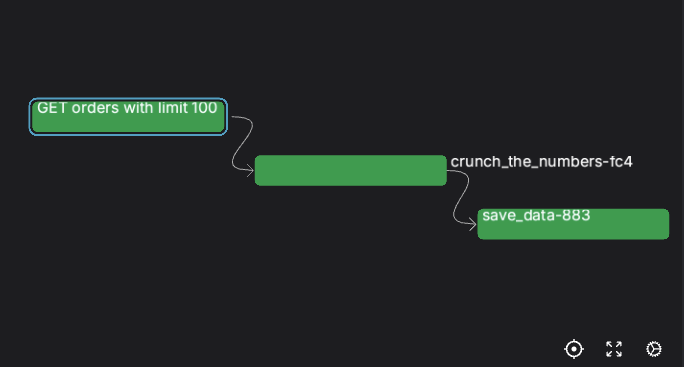
Background tasks
Background tasks are an alternate task execution model where tasks are submitted in a non-blocking manner by one process and executed by a pool of processes. This execution model is particularly valuable for web applications and workflows that need to dispatch heavy or long-running work without waiting for completion to dedicated, horizontally scaled infrastructure. When a task is executed with.delay(), it pushes the resulting task run onto a server-side topic, which is distributed to an available task worker for execution.
Background tasks are useful for scenarios such as:
- Web applications that need to trigger long-running processes without blocking HTTP responses
- Workflows that dispatch work to specialized infrastructure or resource pools
- Systems that need to scale task execution independently from the main application